

¿Es segura la API de informes?
Todos los datos almacenados en BigQuery están cifrados en reposo y en tránsito. Esto significa que cuando los datos se almacenan en los servidores de Google y se transmiten entre esos servidores y el cliente, están protegidos mediante un cifrado seguro.
Además, BigQuery cuenta con controles de acceso integrados que le permiten restringir el acceso a sus datos en función de los roles y permisos de los usuarios. Esto significa que especificamos exactamente quién tiene acceso a sus datos y qué acciones puede realizar con ellos.
BigQuery también admite autenticación y autorización a través de mecanismos estándar como OAuth 2.0 y claves API.
La infraestructura de Google está diseñada para proteger contra amenazas comunes, como ataques de denegación de servicio, filtraciones de datos y accesos no autorizados. Para ello se utilizan diversas medidas de seguridad, como cortafuegos, sistemas de detección de intrusos y auditorías de seguridad periódicas. La API de BigQuery se ha diseñado pensando en la seguridad y emplea una serie de medidas para garantizar que sus datos estén protegidos en todo momento.
¿Con qué frecuencia se actualizan los datos?
Diariamente. La actualización comienza a medianoche UTC+0 con un tiempo máximo de actualización de 12 horas. La actualización cubre todos los datos recibidos hasta la medianoche (UTC+0) del día anterior.
¿Hasta cuándo se remontan los datos?
Todos los datos históricos aprobados para una organización determinada estarán disponibles.
Si soy usuario de Direct Access, ¿cómo me conecto?
Al estar ya en GCP, no habrá ningún problema. Basta con iniciar sesión e intentar consultar las tablas pertinentes a través de la interfaz de usuario o la API.
Recibo el error «El usuario no tiene el permiso bigquery.jobs.create en el proyecto». ¿Qué estoy haciendo mal?
CitrusAd ha otorgado privilegios de visualización de BigQuery a los conjuntos de datos pertinentes para las cuentas que nos haya proporcionado. Esto le permitirá leer las tablas que contienen. En su proyecto, será necesario realizar algunos pasos para poder consultar de forma efectiva estas tablas remotas.
Supongamos lo siguiente:
- Su proyecto = «client-project-123456»
- Your user = [email protected]
- Conjunto de datos de CitrusAd: "insight-platform-external-iam.client_insight_reporting"
Es necesario:
-
Grant [email protected] the bigquery.jobs.create permission within the client-project-123456 project (not the CitrusAd project). You can do this by assigning the BigQuery Job User role.
-
When executing a query, you must run the query within your project (as you only have permissions to read the dataset within the CitrusAd project, not run queries within it). Here is how that might happen using a simple cloud shell command example (executing as [email protected]):
bq query --use_legacy_sql=false --project_id client-project-123456 'SELECT * FROM insight-platform-external-iam.client_insight_reporting.campaign limit 10;'Tenga en cuenta que el proyecto del cliente está configurado como su proyecto, no como insight-platform-external-iam.
Deberá adoptar un enfoque similar con cualquier otra herramienta que utilice. Consulte la documentación de las herramientas proporcionadas para obtener más información, así como la documentación en línea de GCP para acceder a consejos.
Los datos de CitrusAd no están en mi ubicación, ¿cómo puedo obtener los datos en mi ubicación?
Hay muchas posibilidades, pero es fácil crear conjuntos de datos en la misma ubicación que los nuestros para luego realizar transformaciones, consultas, etc., en tablas dentro de esos conjuntos de datos y, finalmente, copiarlos en la ubicación que prefiera.

Existen muchas maneras de copiar entre ubicaciones utilizando la interfaz de usuario, la herramienta de línea de comandos de BQ y la propia API. Para obtener más información, consulte estas páginas de documentación de Google Cloud:
- Gestionar conjuntos de datos | BigQuery
- Referencia de la herramienta de línea de comandos de BQ
- Copiar una tabla de una sola fuente
Si no soy usuario de la API de GCP, ¿cómo me conecto?
CitrusAd le proporcionará las credenciales relevantes en un JSON que puede incorporar a su mecanismo de autenticación.
¿Puedo depurar consultas solo con la API de informes (no con la IU de BigQuery)?
Sí, la API de BigQuery mostrará un código para indicar si se ha producido algún problema y también estarán disponibles mensajes de error.
¿Puedo estimar el coste de una consulta?
Sí, la API dispone de un mecanismo para obtener una estimación en bytes de lo que escaneará la consulta si se ejecuta. Puede utilizar esa estimación multiplicada por la frecuencia con la que realiza la consulta para saber cuánto se acercará a la cuota.
Puede encontrar más información al respecto en la documentación de GCP.
Consulta de ejecución en seco | BigQuery | Google Cloud
¿Qué pasa si supero el límite de cuota?
Consulte su acuerdo con CitrusAd para saber cuál es su cuota. Si no se define específicamente, se establecerá por defecto en 10 TB de exploraciones de datos de consulta al mes.
Su acuerdo también puede implicar un número máximo de llamadas a la API al día. Si no se define específicamente, se establecerá por defecto en 100 llamadas a la API al día.
En caso de que supere su cuota (ya sea en cuanto al escaneado de datos o al número de llamadas), nos pondremos en contacto con usted para conocer sus casos de uso. En función de su contrato, pueden aplicarse costes adicionales.
En caso de uso indebido importante fuera de los términos de su acuerdo (o límites por defecto), nos reservamos el derecho a suspender el acceso.
¿Cuál es un ejemplo de uso de la API de informes?
A continuación se muestran algunos ejemplos que utilizan métodos comunes.
SDK de Google para Python
En este ejemplo podrá:
- Conectarse a BigQuery
- Ejecutar la consulta
- Enviar el resultado a un archivo csv
import google.cloud.bigquery as bq
import pandas as pd
bq_client = bq.Client.from_service_account_json("<REPLACE>.json")
job_config = bq.QueryJobConfig(allow_large_results=True)
query_job = bq_client.query(
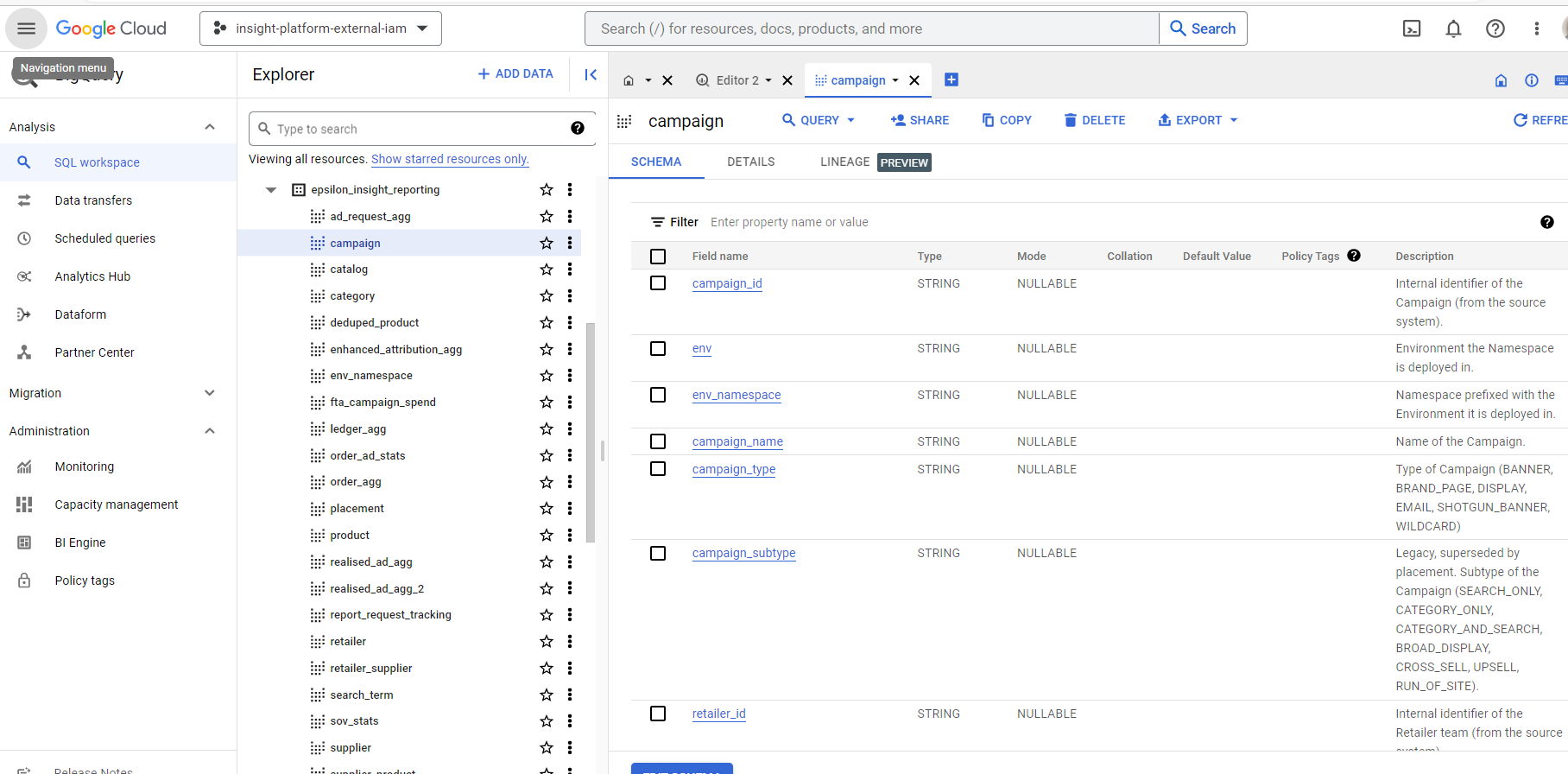
'SELECT count(1) FROM insight-platform-external-iam.<REPLACE>_insight_reporting.campaign
LIMIT 1000', job_config=job_config)
df = query_job.to_dataframe(create_bqstorage_client=False)
df.to_csv(r"C:\Users\<REPLACE>\<REPLACE>.csv", index=False)
print("Run Complete")Hay otros métodos disponibles para estimar los bytes escaneados, etc., antes de ejecutar la consulta.
Consulte la documentación de BigQuery
API de BigQuery | Google Cloud
Si no utiliza GCP, puede hacer referencia a un archivo de credenciales JSON a través de una variable de entorno.
API genérica para Python
import csv
import requests
from google.oauth2 import service_account
PROJECT_ID = "insight-platform-external-iam"
DATASET = "<YOUR DATASET HERE>"
END_POINT = f"https://bigquery.googleapis.com/bigquery/v2/projects/{PROJECT_ID}/queries"
QUERY = f"""
SELECT supplier_id, campaign_id, sum(ad_spend) as ad_spend, sum(clicks) as clicks
FROM `{PROJECT_ID}.{DATASET}.realised_ad_agg`
WHERE ingressed_at BETWEEN '2022-09-01' and '2022-12-31'
group by 1,2
"""
def get_token():
# With service account
credentials = service_account.Credentials.from_service_account_file('./secrets/service-account.json')
scoped_credentials = credentials.with_scopes(['https://www.googleapis.com/auth/cloud-platform'])
# Do token request
def req( method, url, headers, body, **kwargs):
resp = requests.post(url, headers=headers, data=body)
return type('obj', (object,), {'data' : resp.text, 'status': 200})
scoped_credentials.refresh(req)
return scoped_credentials.token
def run_job(token):
resp = requests.post(
END_POINT,
json={
"query": QUERY,
"useLegacySql": False
},
headers={
"Content-Type": "application/json",
"Authorization": f"Bearer {token}"
}
)
return resp.json()['jobReference']['jobId']
def get_query_results(job_id, token):
status_endpoint = f'{END_POINT}/{job_id}?location=australia-southeast1'
completed = False
while not completed:
response = requests.get(status_endpoint, headers={
"Content-Type": "application/json",
"Authorization": f"Bearer {token}"
})
completed = response.json()['jobComplete']
data = response.json()
rows = data['rows']
columns = [c['name'] for c in data['schema']['fields']]
return rows, columns
def extract():
token = get_token()
job_id = run_job(token)
rows, columns = get_query_results(job_id, token)
with open('results.csv', 'w', newline='') as f:
writer = csv.writer(f)
writer.writerow(columns)
for row in rows:
writer.writerow([i['v'] for i in row['f']])
extract()¿Qué pasa si estoy en AWS, etc., y no en Google Cloud, puedo autenticarme y utilizar la API?
Sí, no habrá problema. Le proporcionaremos las credenciales de la cuenta de servicio y podrá hacer referencia a ellas en su solicitud. He aquí un ejemplo.
# TODO(developer): Set key_path to the path to the service account key
# file.
# key_path = "path/to/service_account.json"
credentials = service_account.Credentials.from_service_account_file(
key_path, scopes=["https://www.googleapis.com/auth/cloud-platform"],
)
token = credentials.token
# use the token to do the API calls
# ...
# headers: Bearer ${token}
# ...¿Cómo puedo determinar cuál es la ubicación de cada conjunto de datos que se comparte conmigo?
Esta llamada a la API le indicará en qué ubicación se encuentra cada conjunto de datos.
GET https://bigquery.googleapis.com/bigquery/v2/projects/insight-platform-external-iam/datasets
{
"kind": "bigquery#datasetList",
"etag": "RLU1Ww9C5FdhlcIuRHjW0A==",
"datasets": [
{
"kind": "bigquery#dataset",
"id": "insight-platform-external-iam:acme_insight_reporting",
"datasetReference": {
"datasetId": "acme_insight_reporting",
"projectId": "insight-platform-external-iam"
},
"location": "australia-southeast1"
},
{
"kind": "bigquery#dataset",
"id": "insight-platform-external-iam:acme_acme_analytics",
"datasetReference": {
"datasetId": "acme_acme_analytics",
"projectId": "insight-platform-external-iam"
},
"location": "us-central1"
}
]
}¿Algún consejo sobre buenas prácticas?
En términos generales, si tiene la intención de hacer un uso intensivo de los datos, en particular si tiene acceso a los datos no agregados (solicitudes/anuncios realizados/pedidos/atribución mejorada, etc.), lo mejor es copiar (almacenar temporalmente) las tablas en su propio almacén de datos y, A CONTINUACIÓN, implementar consultas para su lógica empresarial necesaria en dichas copias.
Los usuarios menos exigentes pueden optar por consultar directamente las tablas para obtener resultados específicos.
Es importante mantenerse por debajo de la cuota permitida para garantizar un buen funcionamiento.
Tenga en cuenta también que cada consulta puede descargar 1 GB como máximo, de lo contrario se recibirá un mensaje de error. En caso de que sea necesaria una descarga muy grande, ejecute en su lugar una serie de consultas más pequeñas (por ejemplo, subconjunto de datos por día o proveedor, etc.).
¿Qué sucede si necesito ayuda para elaborar instrucciones SQL adecuadas?
Abra una incidencia para especificar su consulta y le ayudaremos a revisarla. Nos pondremos en contacto con usted para hacerle llegar nuestros comentarios.
¿Algún consejo para usar el paquete Pandas?
Pandas es una de las herramientas de análisis más populares. Para que funcione, es necesario instalar las dependencias pandas-gbq y pydata-google-auth.
El siguiente fragmento es un ejemplo práctico de cómo leer datos de una tabla de BigQuery.
import pandas as pd
from google.oauth2 import service_account
credentials = service_account.Credentials.from_service_account_file('path/to/the/credential/file')
query = 'select * from project.dataset.table'
dat = pd.read_gbq(
query,
project_id='project_id',
credentials=credentials
)More information about the Pandas function can be found here.
¿Algún consejo para usar el paquete PySpark?
Assuming you have a working PySpark environment, you need to provide the correct jar file for the BigQuery connector appropriate to your PySpark version. For instance, PySpark 3.2.* requires spark-3.2-bigquery-0.30.0.jar. The list of the jar files as well as practical code snippets and parameters can be found here.
El siguiente fragmento de código proporciona un ejemplo de cómo ejecutar una consulta.
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName('BigNumeric').config('spark.jars', 'spark-3.2-bigquery-0.30.0.jar').getOrCreate()
spark.conf.set('credentialsFile', 'path/to/the/credential/file')
spark.conf.set('viewsEnabled', 'true')
spark.conf.set('materializationProject', 'yourMaterializationProject')
spark.conf.set('materializationDataset', 'yourMaterializationDataset')
query = 'select * from project.dataset.table'
df = spark.read.format('bigquery').option('query', query).load()
df.show()IMPORTANTE: El parámetro viewsEnabled debe ser true.
Los datos de las vistas se materializan en tablas temporales antes de ser leídos por PySpark, para lo que se necesita el permiso bigquery.tables.create. Por lo tanto, es necesario proporcionar los materializationProject y materializionDataset en los que el usuario sí tiene acceso de escritura.
¿Obtendré un error al solicitar un filtro en la consulta?
Para una tabla particionada es obligatorio un filtro, sin el cual se lanzará un mensaje de error como el siguiente:
No se puede consultar la tabla 'dataset_id.table_id' sin un filtro sobre las columnas 'partitioned_column' que puedan utilizarse para la eliminación de particiones.
Para resolver el error, simplemente agregue un filtro razonable que cubra el rango objetivo, p. ej.
-- this query returns all records available since yesterday
select
*
from
dataset_id.table_id
where
ingressed_at >= date_sub(current_date, interval 1 day)Para saber con qué columna se particiona la tabla (como ingressed_at en el ejemplo anterior), consulte la descripción de la tabla en cuestión.
¿Cómo puedo solicitar acceso?
Proceso
Debe abrirse una incidencia, así como acordarse por escrito los criterios de elegibilidad.
Trabajaremos con el candidato potencial para identificar el nivel de acceso requerido y los ajustes de seguridad y determinar qué cuotas y costes pueden aplicarse.
Criterios de elegibilidad
Para ser considerado como elegible para acceder a la API de informes, el candidato debe cumplir con los siguientes criterios:
General
- El candidato solo puede solicitar acceso a los datos de los espacios de nombres de CitrusAd y de los equipos de los que ya sea miembro o a los que tenga acceso general. El candidato debe especificar cuál de los siguientes supuestos solicita (y aportar pruebas del acceso existente):
- Nivel de entorno (toda una implementación de la plataforma de CitrusAd está dedicada al candidato).
- Nivel de espacio de nombres (el candidato tiene permiso para ver todos los equipos, tanto de minoristas como de proveedores, dentro de un espacio de nombres individual o de una lista de espacios de nombres).
- ID de equipo minorista específico o nivel de grupo.
- ID de equipo proveedor específico o nivel de grupo.
- Además, un integrador puede acceder a un ID de equipo proveedor específico o a nivel de grupo MÁS catálogos completos de productos de minoristas cuando así lo acuerde un minorista caso por caso.
- Los datos de los hechos transaccionales solo pueden facilitarse a los candidatos que cumplan los criterios generales 1a o 1b.
- Los candidatos que no reúnan los requisitos para recibir datos transaccionales de hechos solo tendrán acceso a los datos preagregados de hechos. Los datos se agregarán en resúmenes diarios (con UTC+0 como zona horaria de agregación).
- Los candidatos que solo cumplan los criterios generales 1d no podrán recibir datos de solicitud de anuncios (a diferencia de los datos de anuncios realizados, que sí se facilitarán). El proveedor proporcionará los datos de los productos específicos que se anuncien en los anuncios realizados, EXCEPTO en el caso de los integradores, que podrán recibir catálogos de productos de minoristas cuando así lo acuerde un minorista en función de cada caso.
- Solo se garantiza que los datos dimensionales incluyan las versiones actuales de los registros en cuestión. Se espera que el candidato implemente el seguimiento de los cambios históricos según sea necesario.
- Los datos se actualizan diariamente y se actualizarán a más tardar a las 12:00 UTC+0 para los datos hasta el día UTC+0 anterior completado.
- Se entiende que el acceso es de solo lectura. La API no debe utilizarse para crear objetos en nuestro almacén de datos con ningún fin.
- Cualquier mezcla con otros orígenes de datos debe realizarse en el propio entorno del candidato.
- El candidato debe disponer de un SDK (o equivalente) para acceder a la API de Google BigQuery.
- El candidato debe tener buenos conocimientos de SQL.
- El candidato debe estar familiarizado con los conceptos de CitrusAd y, en caso contrario, se encargará de organizar la formación estándar sobre el producto a través de su gestor de atención al cliente o gestor técnico de cuentas.
- A partir de los documentos proporcionados, el candidato debe desarrollar sus propias soluciones. Si se detecta un problema con un SQL que no se comporta como se espera de acuerdo con la documentación, debe abrirse una incidencia a través de los canales de soporte habituales. Deberá proporcionarse la siguiente información.
- La cuenta a través de la cual se realiza la conexión.
- El SQL exacto al que se llama.
- Una descripción detallada de los mensajes de error que se producen.
- Si el candidato es un minorista, se requiere que se proporcionen las impresiones/clics/pedidos a la plataforma de CitrusAd para poder establecer una imagen completa del ciclo de vida del Anuncio.
- CitrusAd se reserva el derecho a modificar el esquema de vez en cuando. Estos cambios suelen implicar la adición de nuevas columnas a las tablas y vistas existentes y serían compatibles con versiones anteriores. Los candidatos deben estructurar su SQL para nombrar las columnas en lugar de utilizar comodines, etc. En el caso de que un cambio implique la eliminación de una columna o tabla, CitrusAd notificará el cambio con al menos 12 semanas de antelación antes de que se aplique. Las notificaciones se realizarán a través de las comunicaciones de lanzamiento estándar realizadas a los usuarios de la plataforma.
No es obligatorio que un candidato sea usuario de Google Cloud Platform (GCP); sin embargo, existen otros criterios dependiendo de si lo es o no.
Candidato no usuario de GCP
A menos que se acuerde lo contrario, CitrusAd proporcionará al candidato credenciales para una única cuenta de servicio dentro de nuestro entorno.
Salvo acuerdo en contrario, se aplican las siguientes condiciones de incumplimiento:
- Un máximo de 100 llamadas a la API al día.
- No more than 10TB of data scans per month (note, the API has a way of estimating the query scan size prior to execution, refer to Google documentation Dry run query | BigQuery | Google Cloud).
- Si se superan los criterios 1 o 2 de los candidatos no usuarios de GCP, CitrusAd se reserva el derecho a suspender el acceso a su sola discreción.
- Ninguna llamada individual a la API puede descargar más de 1 GB de datos a la vez.
¿Cómo descodifico el archivo de cuenta de servicio?
Recibirá las credenciales de la cuenta de servicio en un formato codificado en Base64 para una transmisión segura. Necesitará decodificar esto antes de usarlo. Aquí tiene ejemplos de cómo decodificar el archivo:
Usando bash:
# Replace encoded-credentials.txt with the file containing your base64 encoded credentials
base64 -d encoded-credentials.txt > service-account.jsonUso de Python:
import base64
# Replace encoded_credentials with your base64 encoded string
with open('encoded-credentials.txt', 'r') as f:
encoded_credentials = f.read()
decoded_credentials = base64.b64decode(encoded_credentials)
with open('service-account.json', 'wb') as f:
f.write(decoded_credentials)Una vez realizada la descodificación, tendrá un archivo service-account.json que podrá utilizar con las bibliotecas cliente de BigQuery, como se muestra en los ejemplos anteriores.
Candidato usuario de GCP
A menos que se acuerde lo contrario, el candidato proporcionará a CitrusAd detalles de no más de 5 cuentas de GCP para que podamos asignar el acceso requerido.
Tenga en cuenta que la cuenta debe tener el rol de usuario de trabajo BigQuery (roles/bigquery.jobUser) asignado.
Se aplican las siguientes restricciones:
- Un máximo de 100 llamadas a la API al día.
- Si se superan los criterios 1 de los candidatos usuarios de GCP, CitrusAd se reserva el derecho a suspender el acceso a su entera discreción.
- Ninguna llamada a la API individual puede descargar más de 1 GB de datos.
Glosario
Entorno
Nombre del entorno físico en el que se implanta la plataforma CitrusAd. Cada uno aloja uno o más espacios de nombres.
Espacio de nombres
Agrupación lógica de todas las entidades que forman parte de una implantación de la solución CitrusAd. Esto incluye los equipos y todos los objetos propiedad de los mismos. Normalmente, un espacio de nombres puede estar formado por un minorista (equipo) y varios proveedores (equipos), además de los usuarios de cada equipo y otras configuraciones relacionadas (catálogos propios de los minoristas, campañas de configuración de los proveedores, etc.). Los equipos (y lo que poseen) pertenecen exclusivamente a un único espacio de nombres (no puede haber un mismo equipo en varios espacios de nombres).
Usuario
Identificador único de un usuario en el sistema CitrusAd. Un único correo electrónico puede tener varios ID de usuario. Cada ID de usuario es único para cada espacio de nombres. Cada usuario tendrá un nombre, apellido, correo electrónico e identificador. Un usuario puede ser miembro de varios equipos y acceder a ellos en la plataforma CitrusAd.
Equipo
Un equipo dentro del sistema CitrusAd. Puede ser un proveedor (anunciante) o un minorista. Los equipos de proveedores suelen crear campañas, los minoristas revisan las campañas y realizan funciones administrativas. Un usuario del sistema CitrusAd puede ser miembro de muchos equipos o de solo uno. Un equipo normalmente tendrá usuarios, campañas y carteras asociados.
Proveedor
Un equipo de proveedores dentro del sistema CitrusAd. Un proveedor suele ser normalmente una empresa matriz de la marca o una serie de equipos por cada marca individual. Los proveedores suelen mantener campañas, administrar saldos de monedero, etc.
Minorista
Un equipo de minoristas dentro del sistema CitrusAd. La mayoría de espacios de nombres solo tendrá un equipo de minoristas. Los minoristas suelen mantener catálogos de productos, revisar campañas, etc.
Campaña
Una única campaña exclusiva configurada con una estrategia de ubicación y segmentación para una selección específica de productos. Por ejemplo, una campaña en el sistema CitrusAd podría estar promocionando los términos de búsqueda de los productos A y B «chocolate» y «chocolates» con una puja máxima de 0,60 USD. Un mismo equipo suele tener muchas campañas.
Catálogo
Un catálogo exclusivo de productos de un minorista en el sistema CitrusAd. Suele ser habitual que un minorista solo sincronice un catálogo de productos con CitrusAd en un único espacio de nombres. Un catálogo tendrá la lista de todos los productos del catálogo del minorista, su nombre, marca, categorías y otros atributos relevantes que se incorporan en el sistema CitrusAd.
Producto
Un único producto exclusivo en el sistema CitrusAd. Un producto tendrá un código de producto exclusivo sincronizado en el catálogo de productos. Un producto puede tener atributos como categoría, taxonomía, marca, etc.
Monedero
Un monedero en el sistema CitrusAd almacena los fondos de un anunciante con el fin de realizar pagos (por ejemplo, el pago de anuncios realizados). Cada monedero tiene un único código de moneda y solo puede invertirse en catálogos de ese mismo código de moneda. El monedero pertenece a un equipo. Un equipo puede tener infinidad de monederos. El monedero se puede archivar. Archivar un monedero hará únicamente que se muestre/oculte en la plataforma; un monedero archivado puede seguir gastando créditos.
Registro
Un registro de eventos que han dado lugar a una transacción en el sistema CitrusAd. Se trata, en la mayoría de los casos, de eventos publicitarios como impresiones o clics en productos patrocinados o anuncios de banner (que generan un débito). También puede tratarse de recargas y ajustes de saldos de un proveedor (créditos). Cada evento tendrá un «motivo», como Productos patrocinados, anuncios de banner, recarga.
Solicitud
Una solicitud realizada al sistema CitrusAd para anuncios. En la solicitud, el minorista especifica una ubicación, así como un contexto como el sessionId de un cliente o los filtros relevantes para la solicitud. En función de la solicitud, CitrusAd enviará de vuelta anuncios de un AdType relevante (por ejemplo, categoría o término de búsqueda) al minorista para que se rendericen al cliente.
Anuncio (realizado)
Un anuncio es un evento publicitario único enviado de vuelta a un minorista para publicarlo a su cliente. Se convierte en un anuncio publicado cuando el minorista devuelve la confirmación de que el anuncio ha quedado al menos impresionado (confirmación explícita de que el anuncio se utilizó realmente, es decir, se publicó). En el sistema CitrusAd, cada anuncio tendrá un ID de anuncio realizado único, que es una referencia para ese evento único.
Categoría
Una categoría es una página del sitio del minorista que forma parte de la taxonomía de su sitio web, como «Panadería» o «Lácteos». Un minorista normalmente solicita anuncios en una página de categorías y especifica este atributo relevante en su solicitud a CitrusAd. Si CitrusAd tiene campañas activas y válidas para la categoría, se devolverán los anuncios.
Término de búsqueda
Un término de búsqueda introducido por un cliente en el sitio web del minorista. Este término de búsqueda se envía a CitrusAd para solicitar anuncios relevantes. Si CitrusAd tiene campañas activas y válidas para el término de búsqueda, se devolverán los anuncios.
Pedido
Un pedido único en el sistema del minorista sincronizado con CitrusAD. Un solo pedido puede contener varios artículos de pedido (al igual que el carrito de un cliente puede contener varios artículos). Una vez que se completa el pedido de un cliente, este se envían a CitrusAd para alimentar la atribución de CitrusAd. Se puede facilitar a minoristas y anunciantes el retorno de la inversión en publicidad (ROAS) y otros KPI importantes.
Atribución
La atribución es un proceso operado en el sistema CitrusAd que asigna anuncios mostrados a un cliente a un pedido enviado. Una navegación típica del cliente sería que vea un anuncio (impresión), haga clic en él (clic), lo añada a su carrito y compre ese artículo (conversión). El pedido se «atribuye» al anuncio único en el que ha hecho clic el cliente. Para que se atribuya un pedido en el sistema CitrusAd, es necesario que se haya interactuado con el anuncio (que se haya visto o se haya hecho clic, según la integración) y que el cliente haya comprado un artículo relacionado con el anuncio. CitrusAd suele utilizar un ID de sesión para atribuir pedidos a anuncios donde el minorista especifica un ID de sesión en todos los puntos de contacto relevantes de una navegación publicitaria. Así es como CitrusAd puede identificar que un solo anuncio, mostrado a un solo cliente, ha dado lugar a un pedido específico.
Fechas
Todos los datos se contabilizan en la zona horaria UTC+0 cuando se agregan.
Límite
Las implantaciones de la plataforma CitrusAd a menudo implican que el minorista solicite más anuncios de los que realmente se mostrarán. Desde una perspectiva analítica, esto puede dar una impresión inexacta del rendimiento real de determinadas métricas.
Por ejemplo, si se ha realizado una solicitud para 20 anuncios (Tipo de anuncio=Producto) y la plataforma ha mostrado 2 anuncios como respuesta, eso representa una «tasa de relleno» del 10 % en la solicitud (2 de 20). Sin embargo, si se entiende que, en la práctica, solo es probable que se usen 4 anuncios (en realidad), sería preferible interpretarlo como un 50 % rellenado (2 de 4).
De ahí la noción de limitación dentro de los informes.
El límite se establece por minorista, donde encontramos un límite disponible para los anuncios de productos y otro para los anuncios de banners (ya que las solicitudes de anuncios de productos suelen solicitar y utilizar muchos más anuncios que banners).
Volviendo al ejemplo, si el límite del producto = 4 para el minorista, las métricas de solicitud informarían de la siguiente manera:
Número de solicitudes de anuncios = 1
Número de anuncios solicitados = 20
Número limitado de anuncios solicitados = 4
Número de anuncios mostrados = 2
Número limitado de anuncios mostrados = 2
Tenga en cuenta que, en el caso de que se mostraran 5 anuncios (es decir, que los anuncios publicados excedieran el límite), las últimas 2 métricas se comunicarían de la siguiente manera:
Número de anuncios mostrados = 5
Número limitado de anuncios mostrados = 4 (se recorta al límite)
Los límites no son obligatorios. En caso de que no se especifiquen, los resultados con y sin límite serían los mismos.
Atribución mejorada
La plataforma CitrusAd realiza atribuciones tal y como se describe en la sección Atribución (ver más arriba).
El subsistema de informes también puede detectar y marcar otros escenarios de atribución según el minorista (atribución mejorada).
Los escenarios son:
- Vista de impresión a través de atribución
- Un pedido se ha atribuido a un anuncio que se ha visualizado para el mismo producto en el mismo ID de sesión (es decir, ha sido una impresión y no un clic).
- Atribución de clics de halo
- Se ha atribuido un pedido a un anuncio en el que se ha hecho clic para un producto perteneciente al mismo nivel de halo en el mismo ID de sesión. El nivel de halo más común es la marca (es decir, el producto del anuncio y el producto del pedido son diferentes, pero pertenecen a la misma marca). Otros tipos de halo son posibles, dependiendo de la implantación. Por ejemplo, el halo puede ser más específico y requerir que el anuncio y el pedido sean para productos que tengan una categoría común además de una marca común. La taxonomía minorista establecida por producto en el catálogo se utiliza para definir este nivel adicional de detalle en el halo.
Version: 1ace13f